네이버 블로그로 이전했습니다.
https://blog.naver.com/moongda0404/222729505732
[Python Data Analysis 분석 5] 데이터 분석 - 파이썬 연관관계 분석(음식 메뉴)
*본 글은 Python3을 이용한 데이터 분석(Data Analysis)을 위한 글입니다. 연관관계 분석을 하는 이유는...
blog.naver.com
*본 글은 Python3을 이용한 데이터 분석(Data Analysis)을 위한 글입니다.
연관관계 분석을 하는 이유는 특정 데이터가 있을 때, 다른 데이터도 존재하는 확률을 알아보기 위함입니다. 예를들면 마트에서 맥주를 살 때, 기저귀를 사는 경우는 얼마나 되는지 연관성을 구해보는 경우가 있습니다.
상관관계 VS 연관관계
-상관관계 : 데이터A가 변화할 때 데이터B가 변하는 영향의 정도
-연관관계 : 데이터A가 있을 때 데이터B가 같이 있는 정도
이번 글에서는 식당 데이터를 가지고 상관관계 분석을 해보겠습니다.
지난 글에서 (데이터 분석 - 식당 데이터 분석해보기) 언급했던 대화에 대한 답을 알 수 있습니다.
손님 : "어떤 메뉴를 주로 먹나요?"
직원 : "토마토파스타와 마르게리따 피자를 함께 추천드려요"
먼저 데이터를 보겠습니다.
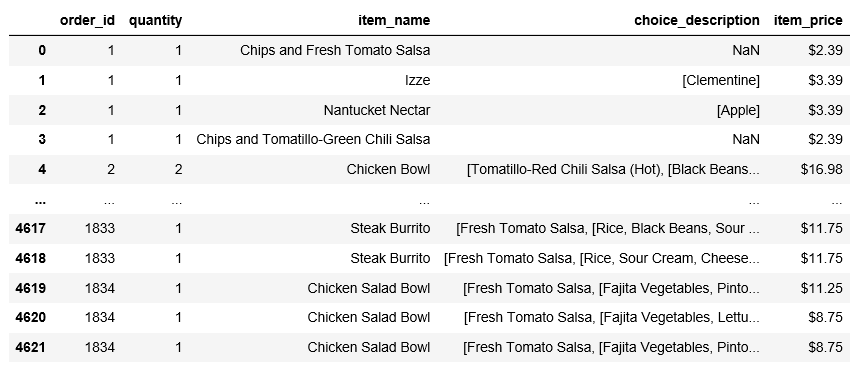
order_id가 같은 것끼리 item_name을 묶으면, 한 테이블당 주문한 메뉴의 구성을 알 수 있습니다.
연관분석 함수를 쓰려면 DataFrame을 list로 만들어야합니다.
그럼 다른 데이터는 지우고, item_name을 order_id에 따라 그룹짓도록 하겠습니다.
order_id가 1834까지 있기 때문에, 리스트의 크기를 1835로 해서 2차원 리스트를 만듭니다.
df_tmp=df[['order_id','item_name']]
df_tmp_arr=[[]for i in range(1835)]
num=0
for i in df_tmp['item_name'] :
df_tmp_arr[df_tmp['order_id'][num]].append(i)
num+=1
order_id가 1부터 시작이다 보니, 0은 null값으로 들어갔군요. pop()으로 제거하고 계속하겠습니다.
그리고 한테이블에 같은 메뉴를 다수로 시킨 경우도 있으니, 중복값을 제거하는 set()도 사용합니다.
df_tmp_arr.pop(0)
num=0
for i in df_tmp_arr :
df_tmp_arr[num] = list(set(df_tmp_arr[num]))
num+=1
df_tmp_arr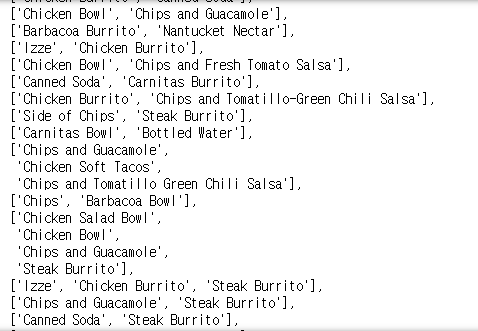
네 그럼 이제 잘 나왔습니다. 이 리스트를 토대로 연관분석 함수를 돌려보겠습니다.
from mlxtend.preprocessing import TransactionEncoder
from mlxtend.frequent_patterns import apriori, association_rules
te = TransactionEncoder()
te_ary = te.fit(df_tmp_arr).transform(df_tmp_arr)
df = pd.DataFrame(te_ary, columns=te.columns_)mlxtend는 통계분석 기능을 지원해주는 파이썬 라이브러리입니다.
모든 데이터에 대해, 각 리스트(행마다) 존재하면 True, 없으면 False로 나타냅니다.
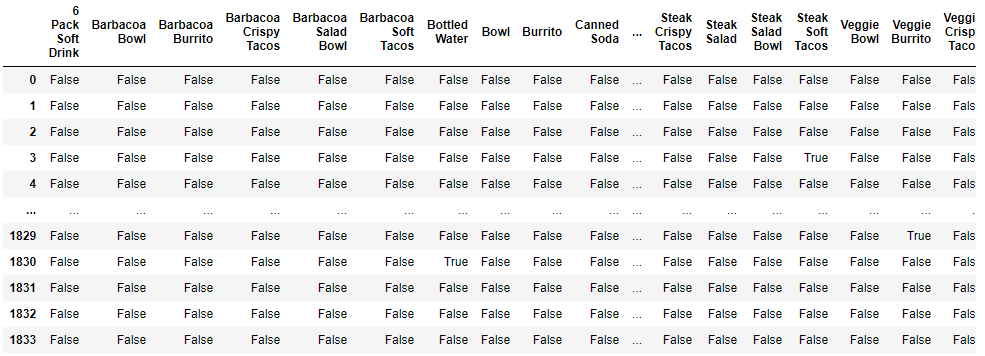
이렇게 변환한 이유는 어프라이어리(apriori)알고리즘을 적용하기 위해서입니다.
그럼 해당 테이블 df를 가지고 '지지도'가 0.05이상인 데이터를 뽑아보겠습니다.
*지지도(support) : 전체 항목 중(행들 중) x와 y를 모두 포함하는 경우의 비율
(ex : 메뉴를 여러개 시킬 때, 치킨이랑 콜라가 포함되는 경우는 전체 중 얼마나 되는지)
frequent_itemsets = apriori(df, min_support=0.05, use_colnames=True)
frequent_itemsets
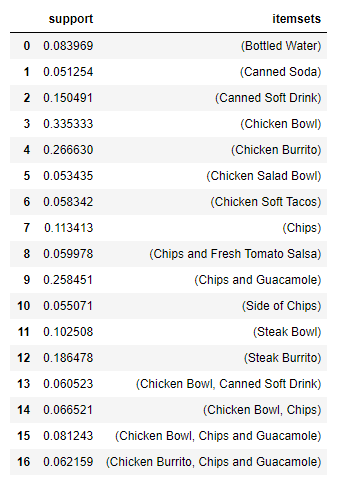
itemsets가 1개인 경우는 놔두고, 2개인 경우를 보면 두 item이 서로 연관이 있음을 알 수 있습니다.
*신뢰도(confidence) : x가 있을 때 y도 있는 비율(조건부 확률)
즉, 치킨이 포함 된 메뉴 구성 중 치킨과 콜라가 있는 비율 ▶ n(치킨U콜라) / n(치킨)
*향상도(lift) : 우연적 기회(random chance)를 벗어나기 위한 값. 1이라면 우연적인 경우로, x와 y의 관계가 독립이지만, 1보다 크거나 작다면 우연이 아닌 필연적인 관계에 있음.
*향상도 = 신뢰도 / 지지도
향상도가 최소 1이상인 연관 관계 출력
association_rules(frequent_itemsets, metric="lift", min_threshold=1)antecedents : 조건절
consequents : 결과절
→만일 (조건절)이라면 (결과절)
그럼 이제 손님이 "어떤 메뉴를 주로 먹나요?" 에 대해,
'Chicken Bowl'을 먹는다면 'Canned Soft Drink'를 함께 먹거나,
'Chicken Bowl'을 먹을 때 'Chips'를 주로 함께 먹는다고 말 할 수 있습니다.
다음 시간에는 분석을 마친 뒤 진행하는 분석모델링을 진행해보겠습니다. (회귀분석/분류모델)
'데이터 분석 기초 > 분석 기법' 카테고리의 다른 글
| [Python Data Analysis 분석 7] 데이터 분석 - 파이썬 선형 회귀분석(2/2) (1) | 2020.06.16 |
|---|---|
| [Python Data Analysis 분석 6] 데이터 분석 - 파이썬 선형 회귀분석(1/2) (6) | 2020.06.16 |
| [Python Data Analysis 분석 4] 데이터 분석 - 파이썬 상관관계 분석(타이타닉) (1) | 2020.06.09 |
| [Python Data Analysis 분석 3] 데이터 분석 - 식당 데이터 분석해보기(3/3) (2) | 2020.06.08 |
| [Python Data Analysis 분석 2] 데이터 분석 - 식당 데이터 분석해보기(2/3) (3) | 2020.06.07 |




댓글