네이버 블로그로 이전했습니다.
https://blog.naver.com/moongda0404/222729175070
[Python Data Analysis 기초 4] 파이썬 데이터 전처리 연습
*본 글은 Python3을 이용한 데이터 분석(Data Analysis)을 위한 글입니다. 이번 글에서는 분석 진행을 ...
blog.naver.com
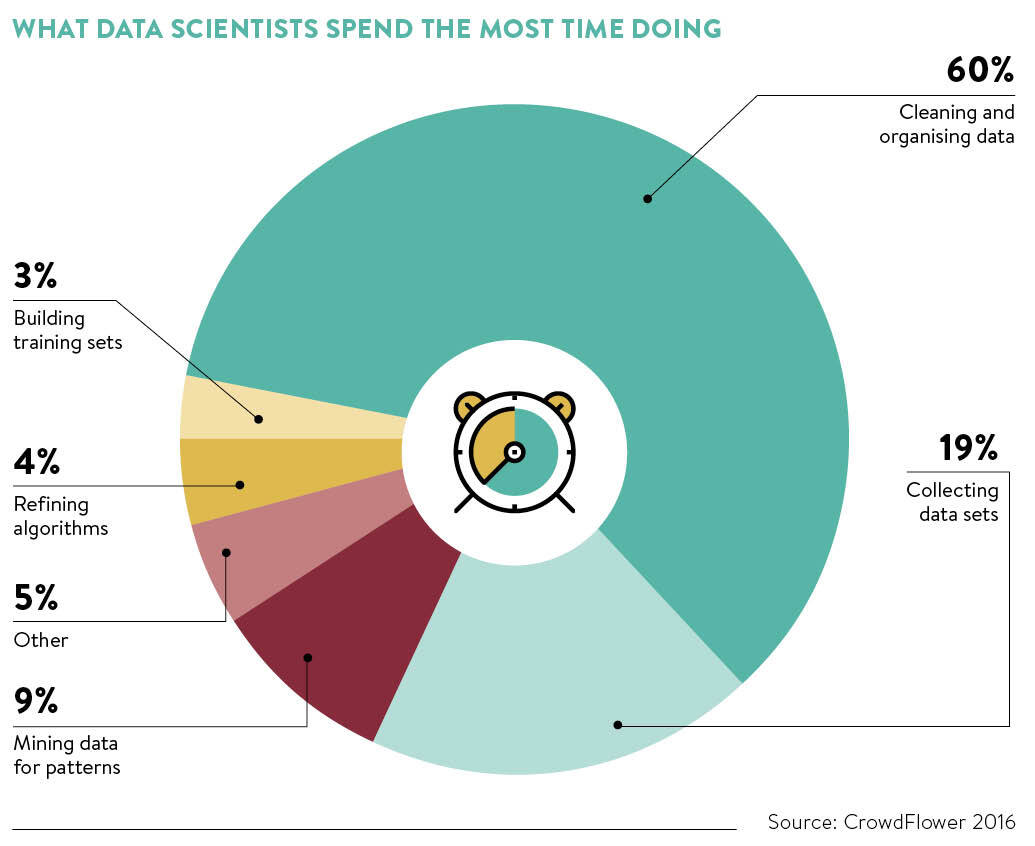
데이터 전처리는 모든 데이터 분석 프로젝트 절차에서 가장 많은 시간이 소모되는 과정인만큼(전체의 60%), 간단한 것들은 바로바로 넘길 수 있도록 익숙해지는 것이 좋을 것 같습니다.
그동안 포스팅 해 온 글에서 사용했던 전처리 함수들에 대해, 리뷰해보는 시간을 가지겠습니다.
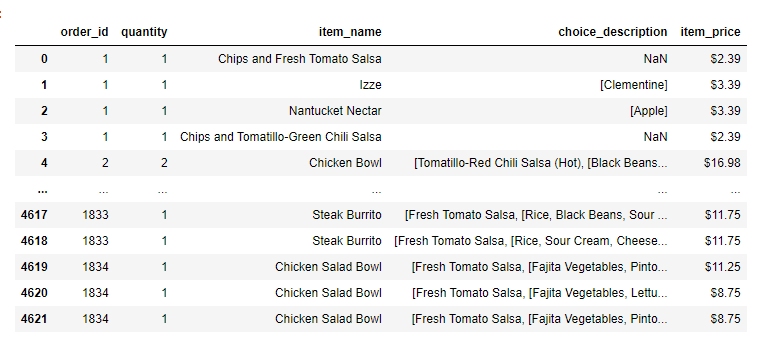
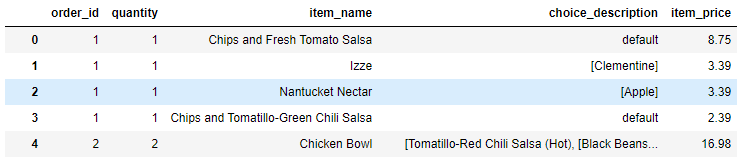
첫 글에서 사용하던 데이터 테이블을 가져왔습니다.
여기서 'item_price'는 음식의 가격인데, 가게의 매출을 알아보기 위해 sum() 함수를 쓰고 싶습니다.
1. str타입을 float로 변환
'$2.39'와 같은 데이터를 보니, str타입입니다. '$'를 삭제하고, 숫자로 변환하겠습니다.
- '$'제거 : 문자열에서 특정 문자를 제거하는 방법은 여러가지가 있습니다. 저는 이중에서 대표적으로 쓰이는 strip()과 re.sub()를 사용해보겠습니다.
strip() : 좌우끝 특정 문자 제거
num=0
for i in df['item_price'] :
df['item_price'][num]=i.lstrip('$')
df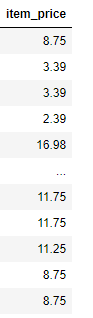
re.sub() : 지정한 문자를 제외한 모든 문자 제거 (ex : 알파벳을 제외하고 모두 제거 등)
import re
num=0
for i in df['item_price'] :
df['item_price'][num] = re.sub(pattern ='[$]',repl='',string=i) #알파벳 제외 모두 제거 : re.sub(pattern='[^a-zA-Z, -]',repl='',string=i)
num+=1
df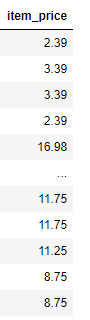
*하지만 위의 두 방법은 반복문을 사용해야하기에, 데이터 크기가 커지면 시간이 너무 오래걸립니다.
그래서 방법을 찾던 중 lambda함수를 사용해 기존에 몇시간이 걸리던 작업을 단시간에 해결할 수 있게 됐습니다.
반복문 사용할 경우
num=0
for i in df['item_price'] :
df['item_price'][num]=i.lstrip('$')
df
lambda함수를 통한 처리
df['item_price']=df['item_price'].apply(lambda x : x.lstrip('$'))
df.
.
.
.
이제 데이터 타입을 str→int로 바꿔줍니다.
df['item_price']=df['item_price'].astype(float)
그럼 이제 합칠 수 있겠군요
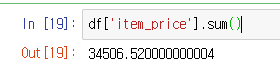
매출이 3만4천달러..부럽습니다.
2. NaN 및 특수 문자 제거
그럼 이제 다른 시도를 해보겠습니다. 'choice_description'을 보니 결측값(NaN)도 보이고, 2차원 리스트로 보여주려 했는지 [ [], [] ] 형태의 데이터도 있습니다.
NaN을 'default'라는 문자로 바꾸고, '['와 같은 괄호를 삭제해보겠습니다.
우선, 결측값이 있는지 찾아보겠습니다.
찾아보니 'choice_description'에만 1246개의 'NaN'이 존재합니다.
|
df.isnull().sum()
|

NaN은 'float'타입입니다. 먼저 NaN을 처리하지 않으면 string함수인 strip이나 sub는 에러가 납니다.
fillna()를 이용해, 결측값을 default로 매우겠습니다.
df['choice_description']=df['choice_description'].fillna('default') df
그럼 이제, 대괄호를 지워보겠습니다.
위와 마찬가지로 strip()이나 re.sub()를 사용 할 수 있는데, 데이터를 보시면 문자열의 사이사이에 '['가 있기에, strip은 사용할 수 없습니다. re.sub()를 이용해 지우겠습니다.
num=0
for i in df['choice_description'] :
df['choice_description'][num]=re.sub(pattern='[^a-zA-Z, ]',repl='',string=i) #[^a-zA-Z,] 은 알파벳과 ',' 그리고 공백을 제외하고 모두 지우겠다는 의미.
num+=1
df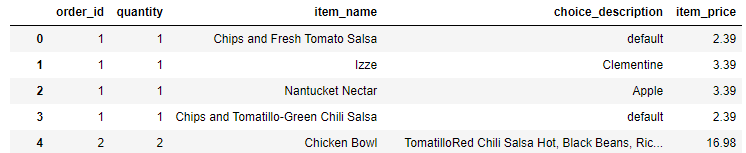
이제 연관분석을 위해 2차원 배열로 만들어야 하는 경우, split(',')을 사용하여 쪼갤 수도 있게 됐습니다.
3. List → DataFrame
파이썬 List를 pandas함수 사용을 위해 DataFrame 함수로 바꿔야하는 경우가 꽤 있습니다.
이때는 pd.DataFrame() 함수를 씁니다.
import pandas
df=pd.DataFrame(list,columns=['columns name'])
4. Series → DataFrame
pandas함수를 쓰면 결과물이 Series 타입으로 나오는 경우가 많습니다. 이 결과물을 토대로 새로운 pandas 함수를 쓰려면, DataFrame 타입으로 변경을 먼저 해야합니다.
이때는 to_frame()을 쓰면 간단히 해결됩니다.
temp_df=temp_series.to_frame()
5. DataFrame 칼럼 추가/삭제
- 추가 : 추가는 특정 선언없이 바로 적용이 가능합니다.
df['new columns']='new'

-삭제 : drop()함수를 사용해 삭제합니다.
df=df.drop(['new columns'], axis=1) #axis=1 칼럼을 의미

▼

6. DataFrame 행 삭제 : 특정 칼럼의 조건에 따라 행을 삭제합니다.
index_tmp=df_tmp[df_tmp['item_name']=='Izze'].index
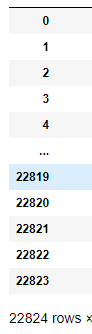
df_tmp=df_tmp.drop(index_tmp)삭제 후 행의 갯수가 변하는데, index는 그대로라서 계산에 에러가 나는 경우가 있습니다.

행 삭제 후 인덱스 개수는 22824개인데, 인덱스는 39673까지 있습니다.
여기서 인덱스 정리를 위한 함수를 사용합니다.
df_tmp=df_tmp.reset_index(drop=True)
7. Groupby를 통한 문자열 통합
groupby를 사용할 경우, 대상이 되는 결과의 합을 숫자가 아닌 문자 그대로 보고 싶은 경우가 있습니다.
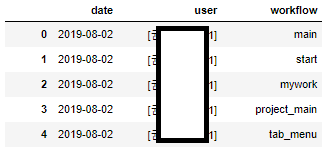
위와 같은 테이블에서 date와 user가 같은데, workflow열의 값이 다릅니다.
date와 user를 기준으로, workflow를 한 행으로 보여주려면 다음과 같이 진행하면 됩니다.
df.groupby(by=['date','user'], as_index=False).agg(lambda x : ','.join(x))
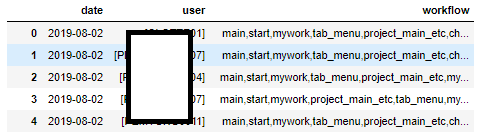
위와 같은 결과를 가지고 조금 다듬어 연관분석등에 사용 할 수 있을 것 같습니다.
.
.
.
.
.
분석을 진행하며 추가로 필요한 기능을 찾게 된다면 계속해서 업데이트하겠습니다.
다음 시간에는 웹크롤링에 대해 설명해보겠습니다.
'데이터 분석 기초 > 파이썬 관련 기초' 카테고리의 다른 글
| [Python Data Analysis 기초 5] 파이썬 웹크롤링 (3) | 2020.06.27 |
|---|---|
| [Python Data Analysis 기초 3] 데이터 분석 환경 설정(3/3) - Jupyter notebook & python 라이브러리 사용법 (0) | 2020.06.05 |
| [Python Data Analysis 기초 2] 데이터 분석 환경 설정(2/3) - Jupyter 경로 설정 (0) | 2020.06.05 |
| [Python Data Analysis 기초 1] 데이터 분석 환경 설정(1/3) - 기본 프로그램 설치 (0) | 2020.06.04 |




댓글