네이버 블로그로 이전했습니다.
https://blog.naver.com/moongda0404/222729182051
[Python Data Analysis 기초 5] 파이썬 웹크롤링
*본 글은 Python3을 이용한 데이터 분석(Data Analysis)을 위한 글입니다. 이번 글에서는 웹크롤링을 사...
blog.naver.com
*본 글은 Python3을 이용한 데이터 분석(Data Analysis)을 위한 글입니다.
이번 글에서는 웹크롤링을 사용하여, 네이버에서 삼성전자 주가 정보를 가져와보겠습니다.
먼저 웹크롤링 라이브러리를 설치합니다.
pip install selenium
파이썬에서 유명한 웹크롤링은 'BeautifulSoup' 인데, 저희는 'selenium'을 익힙니다.
이유는 html은 정적html과 동적html 이라는, 두가지의 html이 있는데 'BeautifulSoup'은 동적html을 가져오기 힘듭니다.
BeautifulSoup : 가볍고 빠르지만 동적Html을 가져오기 힘들다.
Selenium : 느리고, 메모리를 많이 차지하지만 인터넷에서 데이터를 가져오기 수월하다.
자, 이제 selenium client를 설치했으니 크롤링을 위한 엔진을 다운받아야합니다.
Firefox : https://github.com/mozilla/geckodriver/releases
Chrome : https://sites.google.com/a/chromium.org/chromedriver/downloads
Edge : https://developer.microsoft.com/en-us/microsoft-edge/tools/webdriver/
보통 Firefox가 제일 크롤링이 잘 된다고 하지만 여기서는 크롬을 사용하겠습니다.
저는 83버전을 다운받았습니다. (크롬브라우저 버전이랑 동일해야 함)

크롬 버전 확인은 chrome://settings/help 에서 보실 수 있습니다.
압출을 풀면 'chromdriver.exe'라는 실행 파일이 있는데, 웹크롤링 파일 저장 경로에 가져다 두겠습니다
이제 jupyter notebook으로 돌아와, 웹크롤링을 실행시킵니다.
네이버 금융에서 제공하는 삼성전자 주가 테이블을 읽어옵니다.
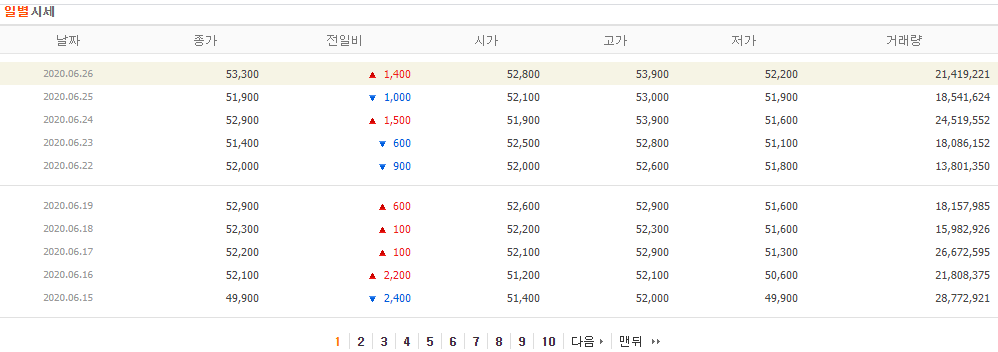
여기서는 날짜, 종가, 거래량을 가져오는데, 한 페이지당 10개의 데이터가 있으니 대략 1년치를 가져오려면 페이지를 40번째 까지 가져와야합니다.
*xpath를 이용해 가져오기
인터넷창에서 F12를 누르면 개발자 모드가 켜집니다. 개발자모드에서 아래 element select(빨간 박스)를 누르고 종가에 표시된 수치를 클릭합니다.
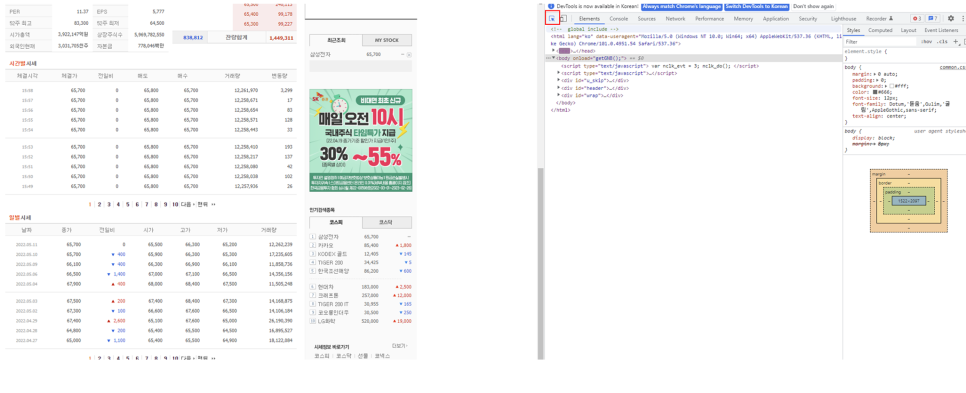
그러면 위와 같이 뜨는데, 클릭 후 오른쪽 개발자모드 창에서 해당 속성이 위치하는 소스코드로 이동합니다.
파란색 음영으로 표시된 줄이 해당 속성인데, 마우스 오른쪽 클릭 - copy - copy XPath를 누릅니다.
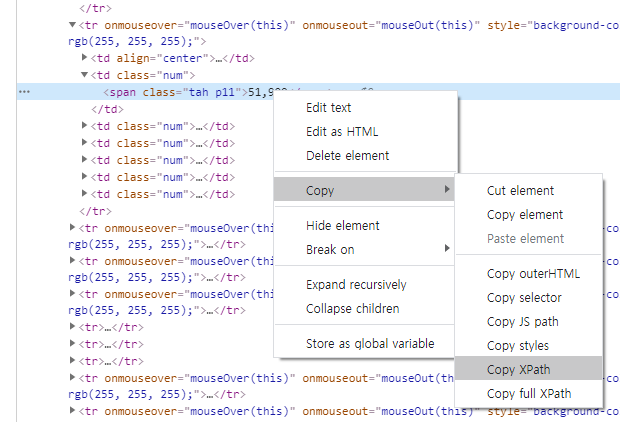
그럼 아래와 같은 소스코드가 복사가 되는데, 이런식으로 속성을 가져올 수 있습니다.
이밖에 html 태그의 class, id 등으로도 불러올 수 있는데 XPath가 가장 무난하게 사용가능합니다.
/html/body/table[1]/tbody/tr[*]/td[2]/span # 1,2,3,4,5...다 불러옴
위의 path를 보면 그 다음 행의 숫자를 찍었을때와 달라지는 부분이 있습니다.
tr[3] 부분과 tr[4]부분이 각각의 행에서 '종가'를 가리키는 부분이라, 페이지 내의 전체 종가를 불러오려면 모든 값을 포함시키는 '*'를 사용합니다.
그럼 첫페이지를 읽어봅니다.
import pandas as pd from selenium
import webdriver
import time chromedriver = './data_web_crawl/chromedriver.exe'
driver = webdriver.Chrome(chromedriver)
driver.get('https://finance.naver.com/item/sise_day.nhn?code=005930&page=1') # 크롤링할 사이트 호출
cost_data_list = list() #읽어온 data를 하나의 list에 모두 담기위함
cost_data=driver.find_elements_by_xpath('//html/body/table[1]/tbody/tr[*]/td[2]/span')
for k in cost_data : cost_data_list.append(k.text) #k.text로 webelement에 담겨있는 text를 불러옴.
for i in cost_data : print(i.text)
driver.quit() #webdriver 종료.
실행하면 인터넷이 잠시 떳다가 사라지는데, 인터넷을 직접 켜서 데이터를 읽어온 뒤 종료하는 것입니다.
잘 실행이 된다면 결과값을 확인해보고 다음 순서로 넘어가겠습니다.
첫페이지만 읽어올게 아니라, 여러페이지를 읽어와야합니다.
여기서는 버튼을 클릭해서 다음 페이지를 읽어올 수 있습니다.
특히 driver를 여러번 호출해야하기 때문에 WebDriverWait함수를 추가했습니다.
그냥 부르면 에러가 나는 경우가 있습니다.
*에러 : stale element reference : element is not attached to the page document
def find(driver):
href = driver.find_elements_by_xpath('//html/body/table[1]/tbody/tr[*]/td[2]/span')
if element: return href
else: return False
import pandas as pd from selenium
import webdriver
import time
chromedriver = './data_web_crawl/chromedriver.exe'
driver = webdriver.Chrome(chromedriver)
driver.get('https://finance.naver.com/item/sise_day.nhn?code=005930&page=1') # 크롤링할 사이트 호출
cost_data_list = list()
num=1 #페이지는 1, 2, 3, 4 이렇게 돼 있을 때, 번호를 찾아서 클릭하기 위함
for j in range(3) :
#WebDriverWait : 반복문 for로 여러번 driver를 돌릴때,
#해당 드라이버가 끝나기 전에 다음 드라이버를 콜하면 에러가 발생함을 방지
cost_data=WebDriverWait(driver, 10).until(find)
for k in cost_data :
cost_data_list.append(k.text)
num+=1 #개발자모드로 찾아보면 페이지 버튼은 숫자라서 숫자를 찾아 클릭함
btn = driver.find_element_by_link_text(str(num))
btn.click()
time.sleep(1)#WebdriverWait를 위함
for i in cost_data_list :
print(i)
driver.quit()

이와 마찬가지로 했을 때 40페이지까지 약 1년치를 불러오는 소스입니다.
import pandas as pd from selenium
import webdriver
import time
chromedriver = './data_web_crawl/chromedriver.exe'
driver = webdriver.Chrome(chromedriver)
driver.get('https://finance.naver.com/item/sise_day.nhn?code=005930&page=1') # 크롤링할 사이트 호출
date_data_list = list()
cost_data_list = list()
trade_amount_data_list = list()
num=1
for i in range(4) :
for j in range(2,11) :
date_data=driver.find_elements_by_xpath('//html/body/table[1]/tbody/tr[*]/td[1]/span')
cost_data=driver.find_elements_by_xpath('//html/body/table[1]/tbody/tr[*]/td[2]/span')
trade_amount_data=driver.find_elements_by_xpath('//html/body/table[1]/tbody/tr[*]/td[7]/span')
for k in date_data : date_data_list.append(k.text)
for k in cost_data : cost_data_list.append(k.text)
for k in trade_amount_data : trade_amount_data_list.append(k.text)
num+=1
btn = driver.find_element_by_link_text(str(num))
btn.click()
date_data=driver.find_elements_by_xpath('//html/body/table[1]/tbody/tr[*]/td[1]/span')
cost_data=driver.find_elements_by_xpath('//html/body/table[1]/tbody/tr[*]/td[2]/span')
trade_amount_data=driver.find_elements_by_xpath('//html/body/table[1]/tbody/tr[*]/td[7]/span')
for k in date_data : date_data_list.append(k.text)
for k in cost_data : cost_data_list.append(k.text)
for k in trade_amount_data :
trade_amount_data_list.append(k.text)
btn = driver.find_element_by_partial_link_text('다음')
btn.click()
num+=1
print(len(trade_amount_data))
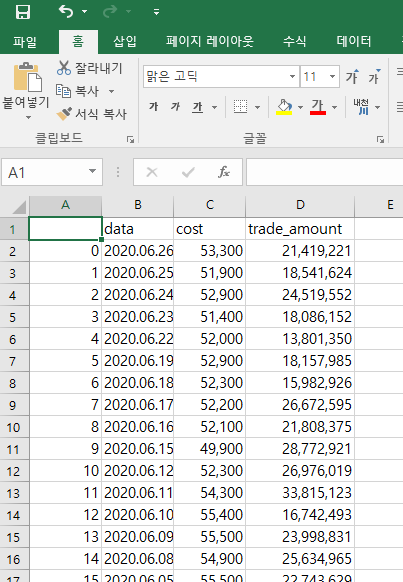
df = pd.DataFrame(list(zip(date_data_list, cost_data_list, trade_amount_data_list)) ,columns=['data','cost','trade_amount'])
df.to_csv('./data/samsung.csv')
driver.quit()가져온 데이터를 dataframe에 저장하여, csv파일로 만들었습니다.
'데이터 분석 기초 > 파이썬 관련 기초' 카테고리의 다른 글
| [Python Data Analysis 기초 4] 파이썬 데이터 전처리 연습 (0) | 2020.06.12 |
|---|---|
| [Python Data Analysis 기초 3] 데이터 분석 환경 설정(3/3) - Jupyter notebook & python 라이브러리 사용법 (0) | 2020.06.05 |
| [Python Data Analysis 기초 2] 데이터 분석 환경 설정(2/3) - Jupyter 경로 설정 (0) | 2020.06.05 |
| [Python Data Analysis 기초 1] 데이터 분석 환경 설정(1/3) - 기본 프로그램 설치 (0) | 2020.06.04 |




댓글