네이버 블로그로 이전했습니다.
https://blog.naver.com/moongda0404/222729530178
[Python Data Analysis 분석 8] 데이터 분석 - 파이썬 시계열분석
*본 글은 Python3을 이용한 데이터 분석(Data Analysis)을 위한 글입니다. 시계열 분석 : 시계열 분석은...
blog.naver.com
*본 글은 Python3을 이용한 데이터 분석(Data Analysis)을 위한 글입니다.
시계열 분석 : 시계열 분석은 말그대로, 현시점까지의 데이터로 앞으로 어떤 패턴의 차트를 그릴지 예측하는 분석기법입니다.
주식차트가 어떻게 진행될지 기존의 차트 모양을 토대로 예측하는 예시가 대표적인데, 이 글에서는 비트코인 차트데이터를 통해 연습해보겠습니다.
# Data Source : https://www.blockchain.com/ko/charts/market-price?timespan=60days
file_path = '../documentum/data/market-price.csv'
bitcoin_df = pd.read_csv(file_path, names = ['day', 'price'])
bitcoin_df
시계열차트의 x축은 'day'이고, y축은 'price'가 될겁니다.
index : day
value : price
day는 단위가 '하루'이기에, 시계열 피처단위로 바꿉니다.
bitcoin_df['day'] = pd.to_datetime(bitcoin_df['day'])
bitcoin_df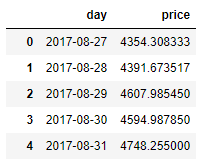
이제 day를 index로 지정합니다.
bitcoin_df.index = bitcoin_df['day']
bitcoin_df.set_index('day', inplace=True)
차트를 확인합니다.
bitcoin_df.plot()
plt.show()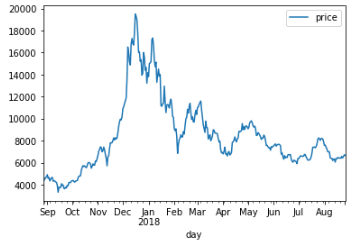
차트의 x축 시간만큼을 토대로, 이후 어떤 수치로 변할지 예측합니다.
파이썬 라이브러리 중 대표적으로 쓰이는 ARIMA를 활용합니다. (상세 알고리즘은 생략합니다.)
ARIMA(Autoregressvie integrated MovingAverage)
AR(자기상관) : 이전의 값이 이후의 값에 영향을 미치고 있는 상황
MA(이동평균) : 랜덤 변수의 평균값이 지속적으로 증가하거나 감소하는 추세
차분은 비정상성을 정상성으로 만들기 위해, 관측값들의 차이를 계산하는 것.
(아래 그림처럼 비정상성에서 정상성으로)
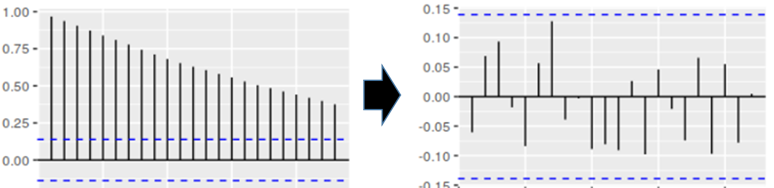
from statsmodels.tsa.arima_model import ARIMA
import statsmodels.api as sm
# (AR=2, 차분=1, MA=2) 파라미터로 ARIMA 모델을 학습합니다.
model = ARIMA(bitcoin_df.price.values, order=(2,1,2))
#trend : constant를 가지고 있는지, c - constant / nc - no constant
#disp : 수렴 정보를 나타냄
model_fit = model.fit(trend='c', full_output=True, disp=True)
print(model_fit.summary())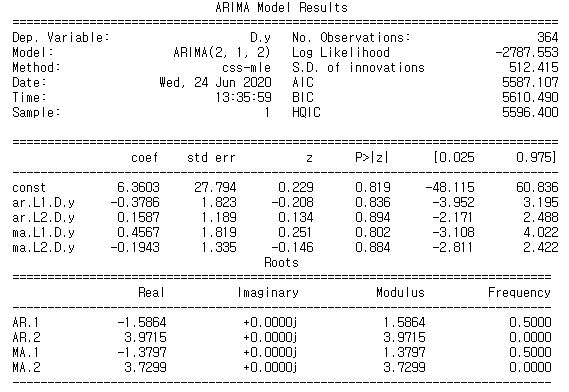
ARIMA 모델 학습에 의한 예측결과를 봅니다.
forecast_data = model_fit.forecast(steps=5) # 학습 데이터셋으로부터 5일 뒤를 예측합니다.
# 테스트 데이터셋을 불러옵니다.
test_file_path = '../data/market-price-test.csv'
bitcoin_test_df = pd.read_csv(test_file_path, names=['ds', 'y'])
pred_y = forecast_data[0].tolist() # 마지막 5일의 예측 데이터입니다. (2018-08-27 ~ 2018-08-31)
test_y = bitcoin_test_df.y.values # 실제 5일 가격 데이터입니다. (2018-08-27 ~ 2018-08-31)
pred_y_lower = [] # 마지막 5일의 예측 데이터의 최소값입니다.
pred_y_upper = [] # 마지막 5일의 예측 데이터의 최대값입니다.
for lower_upper in forecast_data[2]:
lower = lower_upper[0]
upper = lower_upper[1]
pred_y_lower.append(lower)
pred_y_upper.append(upper)
plt.plot(pred_y, color="gold") # 모델이 예상한 가격 그래프입니다.
plt.plot(pred_y_lower, color="red") # 모델이 예상한 최소가격 그래프입니다.
plt.plot(pred_y_upper, color="blue") # 모델이 예상한 최대가격 그래프입니다.
plt.plot(test_y, color="green") # 실제 가격 그래프입니다.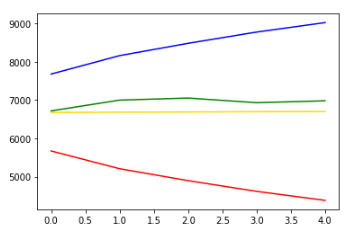
좀더 자세히 보면
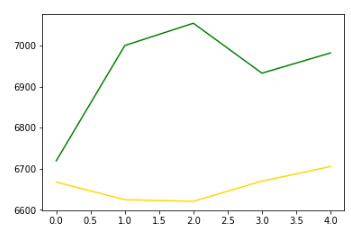
시작일에서 5일 뒤에 가격이 예측과 실제 모두 상승했습니다.
편차가 꽤 크지만 줄일 수 있는 방법이 있습니다.
이번엔 ARIMA가 아닌, 페이스북이 만든 시계열 예측 라이브러리를 이용해보겠습니다.
#라이브러리 설치
conda install -c conda-forge fbprophet
prophet은 '예언자'이라는 뜻인데, 직관적으로 받아들이겠습니다.
Prophet()에서 계절성을 고려하도록 True값을 잡고 모델을 만듭니다.
from fbprophet import Prophet
# prophet을 사용하기 위해서는 다음과 같이 피처의 이름을 변경해야 합니다 : 'ds', 'y'
bitcoin_df = pd.read_csv(file_path, names=['ds', 'y'])
prophet = Prophet(seasonality_mode='multiplicative',
yearly_seasonality=True,
weekly_seasonality=True, daily_seasonality=True,
changepoint_prior_scale=0.5)
prophet.fit(bitcoin_df)# 5일을 내다보며 예측합니다.
future_data = prophet.make_future_dataframe(periods=5, freq='d')
forecast_data = prophet.predict(future_data)
forecast_data[['ds', 'yhat', 'yhat_lower', 'yhat_upper']].tail(5)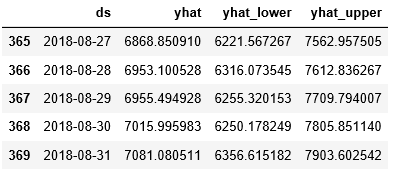
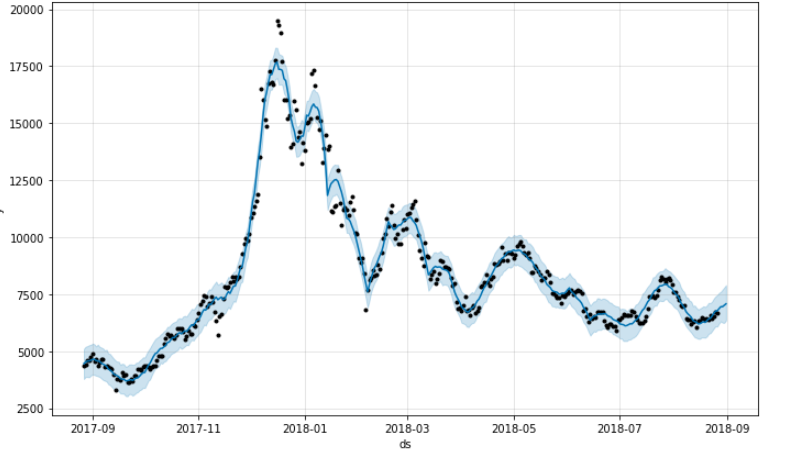
모델링하여 만들어진 forecast_date의 전체 데이터를 보겠습니다.
|
fig1 = prophet.plot(forecast_data)
|
아까 설정했던 계절별 추세를 따로 살펴보는 부분이 있는데, 이는 월,요일,시간별 평균 추세가 어느정도인지 파악 후, 예측에서 시간대별로 가중치를 두기위함입니다.
|
fig2 = prophet.plot_components(forecast_data)
|
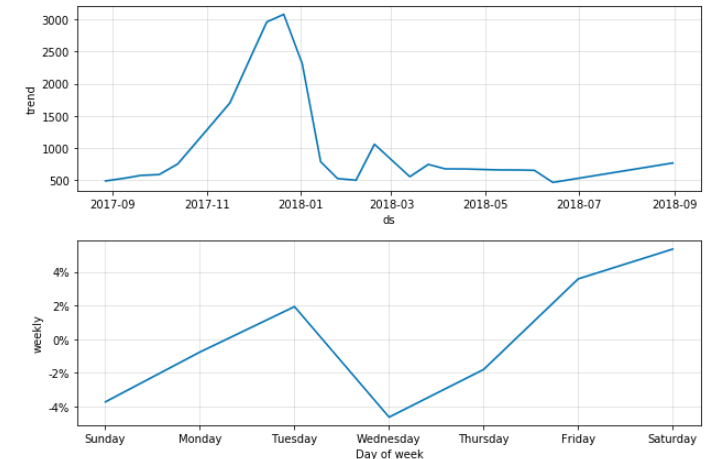
주별로 봤을 땐 수요일에서 토요일까지 주로 상승하는 요일로 나옵니다.
달로 봤을 땐 상반기에 추세가 오르다가 하반기에 감소하네요.
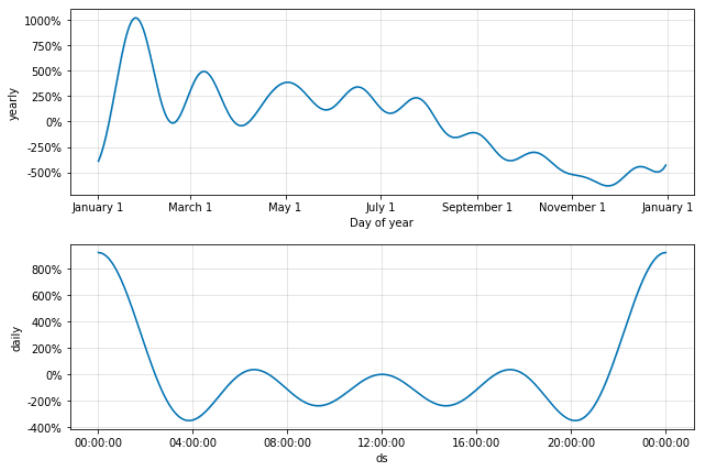
하루로 봤을 땐 한국 저녁 9시 이후 상승하는데, 이는 코인 시장의 메인인 북미 기준으로 이때가 하루 일과의 시작인 아침이라고 판단됩니다.
이제 앞으로의 5일 뒤와 실제 데이터를 비교해보겠습니다.
bitcoin_test_df = pd.read_csv(test_file_path, names=['ds', 'y'])
pred_y = forecast_data.yhat.values[-5:] # 마지막 5일의 예측 데이터입니다. (2018-08-27 ~ 2018-08-31)
test_y = bitcoin_test_df.y.values # 실제 5일 가격 데이터입니다. (2018-08-27 ~ 2018-08-31)
pred_y_lower = forecast_data.yhat_lower.values[-5:] # 마지막 5일의 예측 데이터의 최소값입니다.
pred_y_upper = forecast_data.yhat_upper.values[-5:] # 마지막 5일의 예측 데이터의 최대값입니다.
plt.plot(pred_y, color="gold") # 모델이 예상한 가격 그래프입니다.
plt.plot(pred_y_lower, color="red") # 모델이 예상한 최소가격 그래프입니다.
plt.plot(pred_y_upper, color="blue") # 모델이 예상한 최대가격 그래프입니다.
plt.plot(test_y, color="green") # 실제 가격 그래프입니다.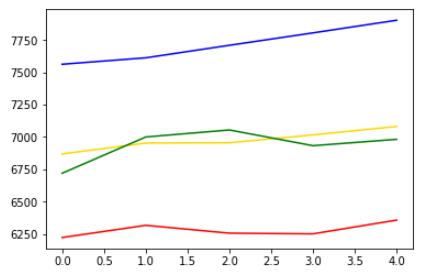
ARIMA를 활용했을 때에 비해 훨씬 오차가 줄어들었습니다.(최대, 최소 허용치 포함)
다시 보면
plt.plot(pred_y, color="gold") # 모델이 예상한 가격 그래프입니다.
plt.plot(test_y, color="green") # 실제 가격 그래프입니다.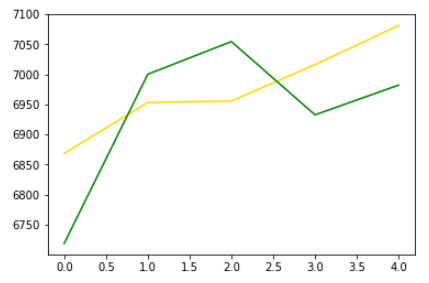
상당히 유사하게 상승하는걸 예측했습니다.
그럼 이제 실제 어제까지의 data를 받아서 앞으로 5일간의 예측을 해보겠습니다.
실제로 어떻게 됐는지 다시 5일 뒤 업데이트 하겠습니다.
한번 도전해보세요 실시간 다운받을 수 있는 링크입니다.
#주의! csv를 열고 header를 지운다음 진행해야 에러가 안 납니다.
file_path='../data/market_price_200624.csv'
bitcoin_df = pd.read_csv(file_path, names=['ds', 'y'])
prophet = Prophet(seasonality_mode='multiplicative',
yearly_seasonality=True,
weekly_seasonality=True, daily_seasonality=True,
changepoint_prior_scale=0.5)
prophet.fit(bitcoin_df)위와 동일하게 진행하고 예측값을 보겠습니다.
# 5일을 내다보며 예측합니다.
future_data = prophet.make_future_dataframe(periods=5, freq='d')
forecast_data = prophet.predict(future_data)|
forecast_data[['ds', 'yhat', 'yhat_lower', 'yhat_upper']].tail(5)
|
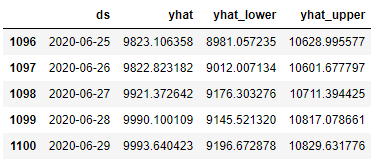
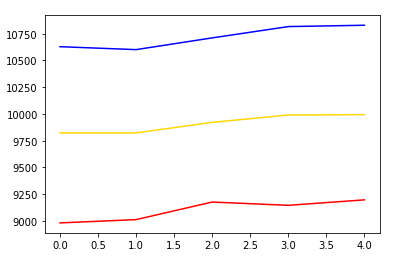
예측은 만달러 가까이로 상승합니다.
그럼 5일 뒤 실제 차트와 얼마나 유사했는지 확인해보겠습니다.
.
.
.
.
.
.
5일 뒤 (2020년 6월 29일 기준)
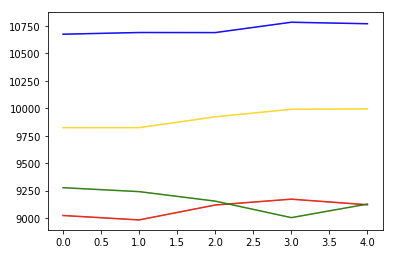
예상 최소값에 걸쳐서 진행됐네요. 맞다고 봐야할지 아닐지..
'데이터 분석 기초 > 분석 기법' 카테고리의 다른 글
| [Python Data Analysis 분석 7] 데이터 분석 - 파이썬 선형 회귀분석(2/2) (1) | 2020.06.16 |
|---|---|
| [Python Data Analysis 분석 6] 데이터 분석 - 파이썬 선형 회귀분석(1/2) (6) | 2020.06.16 |
| [Python Data Analysis 분석 5] 데이터 분석 - 파이썬 연관관계 분석(음식 메뉴) (4) | 2020.06.11 |
| [Python Data Analysis 분석 4] 데이터 분석 - 파이썬 상관관계 분석(타이타닉) (1) | 2020.06.09 |
| [Python Data Analysis 분석 3] 데이터 분석 - 식당 데이터 분석해보기(3/3) (2) | 2020.06.08 |




댓글